Ryerson Computer Science Cps730 Web Tech / Performance
(go back)Mind Map
{kind=link}
Rough Notes
Scalability
Problems
Latency
Amount of time it takes between the request of an http object and the response that delivers it to the client
Traffic
Amount of data being transmitted on a network
Server load
Number of size of resource requests to a web server
Solutions
Proxy Caching
A proxy cache can cache http responses so that subsequent requests for the same resource will be served much faster. This reduces network traffic and load on the web server
Components of the Web
Semantic Components
- Naming infrastructure (URI)
- Document language (HTML)
- Message exchange protocol (HTTP)
System components
- server
- user agent
- proxy cache
Web Application Protocols
HTTP
DNS
DNS servers have zone files that contain records which map IP addresses to www URL's. Frequently or recently requested URL's are typically cached by the server so that they are readily accessible and do not need to be searched for through the zone file. Text file with a list of computer name to IP address mappings (DNS) records. If the local DNS server does not have the record, it performs either a recursive or iterative query request to the root server. Recursive queries are where the receiving DNS server should respond directly to the sender, while iterative would have the receiving DNS server provide the IP address of the next DNS server to query until the record is found
SMTP
Used when a Mail User Agent (a person) wishes to send an email; their email client software uses the SMTP protocol to pass the email to the email server. The email server then relays the message using the same SMTP protocol on to a Mail Transfer Agent (which is yet another SMTP server). The MTA uses DNS (domain name system) to find the IP address of the destination mail server, after which it sends the email (again using SMTP protocol) to that Mail Exchanger (MX) server. From there, the MX server passes the email to a Mail Delivery Agent for delivery to the user's email software. SMTP typically uses port 25 or 587.
#sample SMTP login and send mail: telnet localhost 25 HELO webdev MAIL FROM: [email protected] RCPT TO: [email protected] DATA Subject: test email Hi self, this is a test. .
POP
Used by local email client software to retrieve emails from an email server. When email clients use this protocol, generally what happens is the email client connects to the server, retrieves any new emails to the local computer, then deletes the emails from the server. POP uses port 110 for non-secure communication and port 995 for encrypted communication.
#sample POP login and list mail: telnet webdev 110 USER j2mair PASS ***** LIST
IMAP
Similar to POP, IMAP downloads messages from the mail server to the local client, however it is more typical for IMAP clients to be configured to not delete emails from the server after downloading. This makes IMAP more flexible for using multiple clients to connect to the same email account. For example, one person's PC, Smartphone, tablet, etc, can all use the same account and keep mail synchronized among all their devices. IMAP4 also includes the ability to keep track of folders configured on the server. IMAP typically uses port 143 or 993 for insecure and secure communications respectively.
Networks / Programming
Thread, basic parts:
- Stack
- Register set
- Programming counter
- Data
Thread Models
- user-level
- kernel-level
Sockets
UDP
- fast, unreliable
TCP
- reliable, not so fast
TCP Congestion Control
Used to ensure that the volume of network traffic does not increase to the point where data is dropped due to overloaded network components (like routers). The TCP sliding window protocol is a mechanism used to prevent network congestion. The TCP sender has a congestion ‘window’ size that is the maximum number of unacknowledged segments that can be sent to the receiver at one time. Segments are numbered as they are sent so that the receiver can piece them together in the correct order, and as they are received, an ACK (acknowledgement) is sent back to the sender. When the earliest sent segment has been acknowledged, the window is ‘shifted’ forward so that there is room for later segments to be sent.
Race Conditions
Two processes or threads are vying for the same resource and it is indeterminate as to which will get to it first. Maint types: deadlock, starvation
Solution: semaphores
- Binary semaphore:has just two states
- Counting semaphore: has any number of states
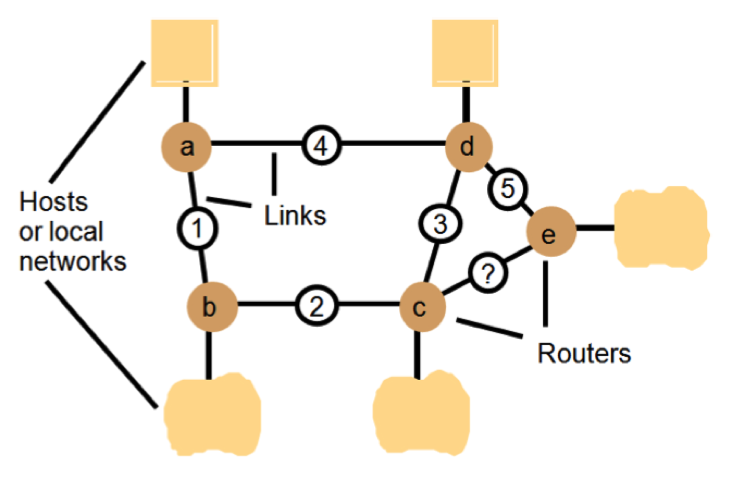
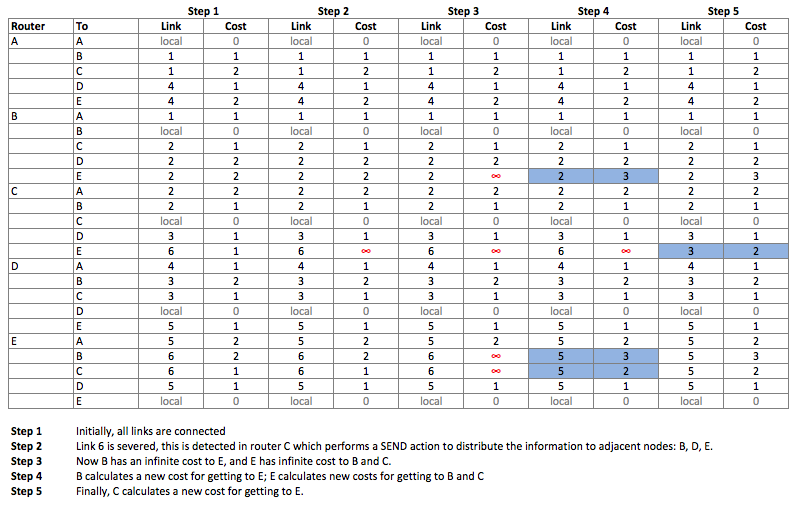
Distance-Vector Routing Algorithm
Example of following a connection-break among routers that employ a simplified version of the Distance-vector routing algorithm
Web workloads
Types of workload
- Inter-arrival times
- Number of requests
- File sizes
- Number of embedded resources
Benchmarking
- Stress testing
- Synthetic workloads
Web Proxy
An intermediary program that could be on the same machine or different machine from where the request originated. Acts on behalf of a set of clients in communication with servers. Acts as a server to clients, and client to other proxies or origin servers
Example: squid proxy cache
- A proxy is viewed as a trusted intermediary
- To maintain user privacy, a proxy must provide end-to-end encryption
Types of Proxy
Caching Proxy
Caches response data.
Transparent Proxy
Does not cache or modify messages as they flow through. Can be used to communicate with non-HTTP systems on behalf of the web browser (such as FTP).
Interception proxy
Examines network traffic
Proxy Chaining
Proxies may act as clients to other proxies. A hierarchy of proxies may be employed. This is occasionally used within a business, with a proxy for each area, and higher-level regional proxies
Web Caching
Replacement policy
Dictates how to decide what should be removed when the cache is full
Least recently used (LRU)
- Just keep a stack in order of request
- Squid uses this by default
Least frequently used (LFU)
- Needs a counter for each item
- Problem
- One object may receive lots of requests all at once, like a popular news item; counter goes very high so it stays in the cache, but it's no longer used -- "cache pollution"
Greedy dual size
GDS associates a 'utility value' with each resource stored in the cache. The value is
cost / size
where cost is the time it takes to bring the resource into the cache (may be based on number of network hops). Items with the greatest cost should be kept in favour of items with a lower cost.
Cachability
Not everything can be cached! Exclusions are based on protocol and content
Protocol-specific cache exclusions
- HTTP requests: OPTIONS, PUT, DELETE, POST (unless has necessary headers)
- HTTP responses headers that indicate cachability: cache-control and expires
Usual content exclusions from caching
- dynamic responses
- very large resources
- responses with cookie information
Important metrics
Hit Ratio
Ratio of number of requests that could be served from the cache (to number that had to go to the server)
Byte-Hit ratio
Ratio of number of bytes that could be served from the cache
Analysis
Temporal Locality
Temporal locality is how recently an item has been accessed
Popularity
Popularity refers to the frequency of access
Cache coherency
Ensuring that what is in the cache accurately matches the server
Consistency checking
- Strong
- Checking the server on each request for freshness
- Weak
Methods
- Lease-based; Eg, item expires in N-may days
Where to cache
- Browser
- Proxy server
Performance
Workload Characterization
In order to analyze performance, we must choose some workload characteristics to study. Commonly chosen for web performance are:
- HTTP message characteristics
- request method
- response code
- Resource characteristics
- Size of requested resources
- popularity
- content-type
- User behavior
- Number of requests
- Inter-arrival time of resource requests
- number of clicks per session
Capturing the mean, median, and variance of these provide the basic necessary statistical information for useful analysis
Characteristic Modelling & Analysis
- Parse logs (like squid logs)
- Put together a histogram for each characteristic
- See if the results match the expected model characteristic
- File-size distribution: Weibul
- Inter-arrival times: Exponential ?
- Popularity: Zipf
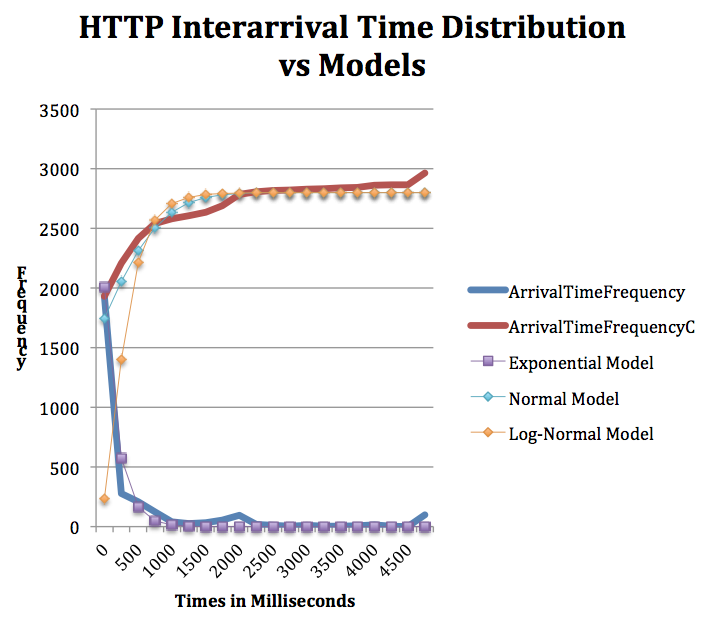
Sample HTTP Resource Request (Inter-arrival) Distribution
This graph contains a very rough distribution of interrarival times of http requests from a sample squid log. Roughly matches the exponential PDF curve
Multimedia
Terminology
Streaming
Overlapping the playout of the data at the receiver with the sender
Buffering
Frame rate
Number of frames (per second) of video that can be delivered to the receiver
Jitter
Delay introduced by the transmission equipment; important for performance metrics
RTSP
Stateful protocol used in realtime multimedia streaming
States
- Init
- Ready
- Playing
- Recording
Compression
Lossless
All of the information is preserved after decompressing. (huffman, Arithmetic, etc)
Lossy
Some information is not recovered after decompression. This saves more space, probably compute cycles as well (transform coding)