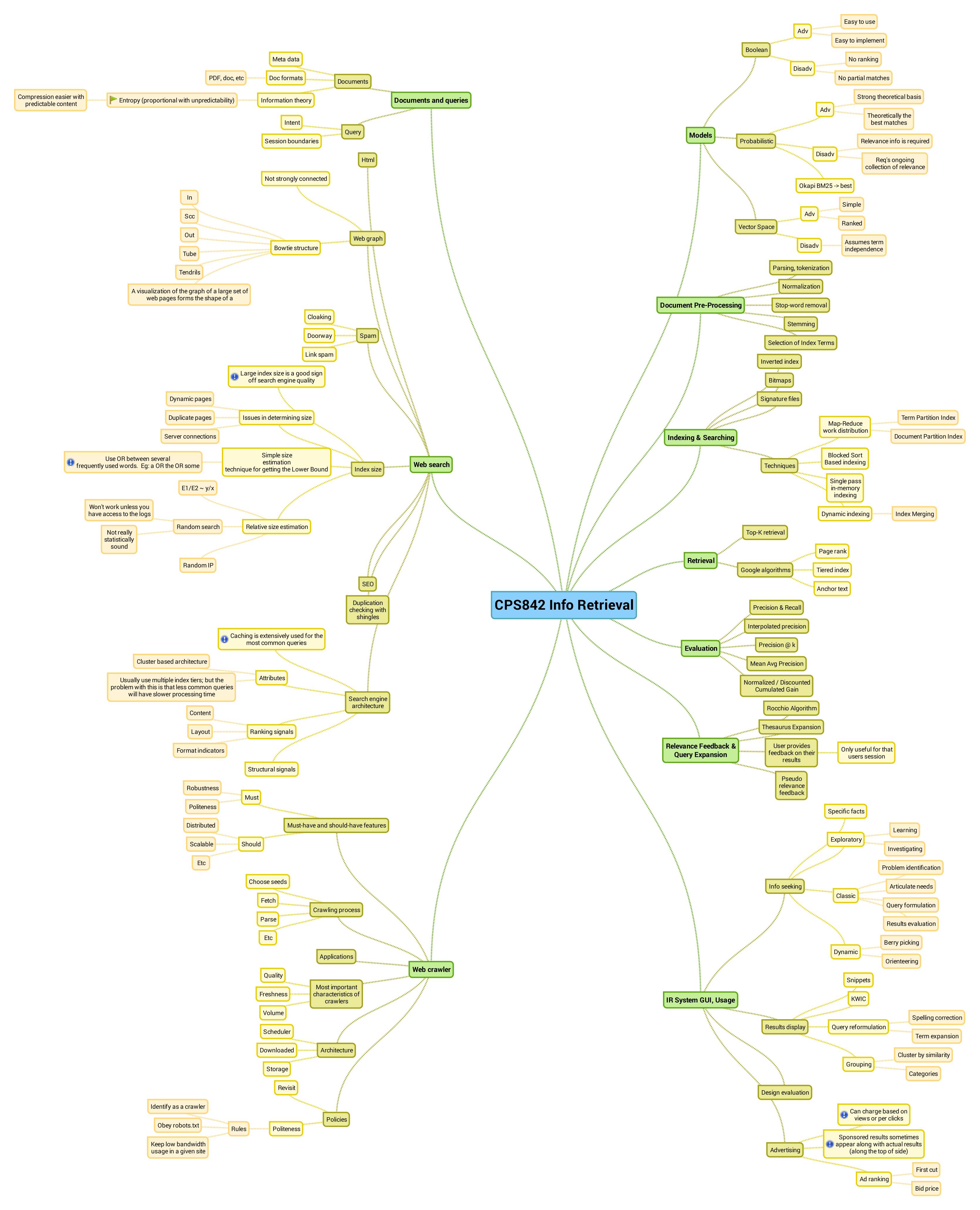
Deals with the representation, storage, organization, etc
Apply text processing, transformation to both input documents as well as user queries -- same transformation; document terms are indexed
IR system does matchmaking and ranks the relevant documents
query | |-> query terms | | -> text processing -> | |-> matchmaking -> return ranked docs documents | |-> index terms |
quadruple representation: [D, Q, F, R(qi, di)]
Based on set theory, Boolean algebra
Use a vector to represent a document, and also to represent the query. Measure the similarity between the query vector and the document vector. Rank is based on similarity
Lucene uses the Vector Space Model
Order or words is not important: John runs faster than Mary is the same as Mary runs faster than John
do the LOG(base10) on the frequency
IDF is larger for terms found in fewer documents
finally, Wij = TFij * IDFi
Where t is the number of terms, the vector space has t dimensions
can use euclidian distance fmla to find distance between query and each document
d: ( 1 1 1 0 1 1 1 ) q: ( 1 1 1 0 0 0 0 )
Euclidian distance... not so good, so use similiarity score by measuring the angle between the vectors
smaller angle means more similar
similarity(dj,q) = vec dj cdot q = SUM (Wij . wiq)
$sim(d,q) = \cfrac{\sum{w_{ij} w_{iq}}}{\sqrt{\sum{w_{ij}^2}\sum{w_{iq}^2}}}$
Longer documents with higher frequency may be favored; so we may want to normalize.
The result is normalized -> between 0 and 1
ni is same as df; so Ranking without Estimate is same as idf fmla
Most popular probablistic model
The major steps in document pre-processing include:
Example of converting from Term Partitioned Index to Document Partitioned Index:
Suppose the goal is 3 servers, with DocIds 1-10,000, 10,001 - 20,000, 20,001 - 30,000
generally better because the query processing workload is distributed on multiple servers; each server can do the intersection on the documents; the central server just needs to union them and sort them
Z0 --> I0 --> I_1 --> I___2 --> I____3
reduce computation cost by eliminating large number of documents without computing their cosine scores
Techniques:
See Precision-Recall curve calculation - usually starts high, drops to zero, sometimes with 3 plateaus
Precision-recall tradeoff
Max precision where recall > % amount
Precision level achieved at some point in the results. Eg, P @ 5 is the precision calculated as of the fifth result
MAP = SUM(precision values) / |Relevant|
Given the total number of relevant documents |R|, take the top |R| from the results and calculate the fraction of relevant documents among that set
Not so common; most common are MAP and NDCG
can discount the very relevant documents that appear low on the list
Feedback is generally only used for query & results optimization for a single user session since one person's query may match another persons's query, but they may find some results more valuable than others
Formula provides the ideal query vector based on the user's input of what is relevant and what is not (depends on the user!)
Standard Rochhio: usually relevant documents given more emphasis, so Beta usually larger than Gamma
Does re-weighting, but does not introduce new terms; does not consider the original query
WordNet - Princeton University
Fill out a matrix of relationships calculuated with the fmlas given in the notes:
t1 t2 t3 t4 ... tn
t1 1 0.1 0.8 0.2
t2
t3
...
Nearest neighbour may not mean they are close to each other in the document, but merely have a high correlation (across docs)
Term is a vector of documents; same as Vector Space model but indexed by term instead of document. See slides for the fmla
From a sample term-doc matrix:
Local is only applied to the top-ranked documents; should help prevent the precision from dropping too much
Local has to be done in real-time based on the results, so it can be slower
There are several processes that people use IR systems to find things...
Like looking for a formula, or a phone number; something quantitative so that you can consider the search finished after finding it.
Show the keywords entered by the user, highlighted in a snippet from the document
Can charge based on views or per clicks
Sponsored results sometimes appear along with actual results(along the top of side)
Large index size is a good sign of search engine quality
Caching is extensively used for the most common queries
Recommend items based on algorithmically estimated preferences and interests
Find the similarity of users based on their ratings on a set of items
Same approach as the User-Based CF, but users and items are inverted in the formulas
Example Item-Based Collaborative Filtering problem
A third option is to combine both the user-based and content-based approaches
$sim(x,y) = {{\sum{(r_{xs} - \bar{r_{x}})(r_{ys} - \bar{r_y})}}\over{\sqrt{\sum{(r_{xs} - \bar{r_x})^2}\sum{(r_{ys} - \bar{r_y})^2}}}}$
See fmla earlier in this note
$rating_{xy} = {1 \over{\sum{sim(x,other)}}} \times \ \sum{sim(x,other)(otherRating_{y})} $
Separating documents into groups
Documents in the same cluster behave similarly with respect to relevance to information needs
Input 'K' is the number of clusters that will be produced. Algorithm is:
A 'bottom-up' clustering algorithm.
{kind=link}